
目次
1. はじめに
2. FileMaker Server 設定のおさらい
3. RAG で使用するデータを登録、管理する
3.1. RAG に必要なスクリプトステップと関数
3.2. RAG スペースへのデータの登録
3.3. RAG スペースの情報の確認
3.4. RAG スペースのデータの削除
4. 質問から適切な回答を得る
4.1.「質問〜回答」の処理の流れ
4.2. 質問を送信して、回答を得るためのスクリプト
4.3. プロンプトのカスタマイズ
5. RAG を運用する上での重要なポイント
5.1. データの取り扱いポリシーに則して AI モデルを選ぶ
5.2. RAG スペースを整備し、ユーザにわかりやすいインターフェースを提供する
6. おわりに
1. はじめに
このブログでは、以前公開したブログ「Claris FileMaker 2025 - AI を活用するための新機能」の内容を踏まえ、その中でも特に注目度の高い RAG(検索拡張生成)を取り上げ、「設定編」「利用編」の 2 部構成で掘り下げて解説しています。
前編の「設定編」では、
- RAG の基本的な考え方
- RAG に必要なもの
- FileMaker Server 2025 の AI モデルサーバーの設定
- API キーの設定
- 利用する AI モデルの選択
までを解説しました。
今回、後編となる「利用編」では、カスタム App を使って社内文書を登録・削除し、実際に質問をして適切な回答を得る方法をご紹介します。
※この「利用編」の手順を実際に操作する場合は、「設定編」の内容に基づき、FileMaker Server での設定が完了している必要があります。設定内容の概要は冒頭でおさらいしますが、詳細については「設定編」でご確認ください。
2. FileMaker Server 設定のおさらい
最初に、「設定編」の内容を簡単に振り返っておきましょう。
まず、RAG を利用するカスタム App を開発するために必要な FileMaker Server での設定は次の通りです。
- FileMaker Server のドメイン名または IP アドレス
- [アクセスには API キーが必要] の設定(ここでは「有効」に設定済み)
- API キー(既に発行し、安全なところへ保存済み)
- RAG スペース ID(ここでは「社内規程」と「顧客対応マニュアル」を設定済み)
また、今回利用する AI モデルは次の通りです。
- テキスト埋め込み(Embedding)
- オープンソース
- paraphrase-multilingual-MiniLM-L12-v2
- テキスト生成
- OpenAI 社
- gpt-4o
では、これから、上記の設定に基づいて、カスタム App での手順を見ていきましょう。
3. RAG で使用するデータを登録、管理する
カスタム App で RAG を利用するには、FileMaker Server 環境を設定した後、カスタム App の RAG スペースに検索対象となる情報を登録し、適宜メンテナンスしながら運用していくことが必要になります。このセクションでは、そうした、RAG で使用するデータの扱いに関する手順や注意点を解説します。
3.1. RAG に必要なスクリプトステップと関数
まず、RAG で使用する主なスクリプトステップと関数の概要を押さえましょう。詳細は、後ほど、サンプル App の実際のスクリプトで確認します。
- [RAG アカウント設定] スクリプトステップ
- RAG スペースを管理するサーバーのエンドポイント、API キーを指定します。
- なお、このスクリプトステップは RAG 用の接続設定のみを行うものです。テキスト生成を行う AI に対する接続設定は、[AI アカウント設定] スクリプトステップで別途指定する必要があります。
- [RAG 処理を実行] スクリプトステップ
- データの追加
- データの削除
- プロンプトの送信
- RAG スペースに対して次の処理を実行します。
- 1 つのスクリプトステップで複数の処理を行えるため、オプションの [処理] を変更して使い分けます。
- GetRAGSpaceInfo 関数
- RAG スペースに関する情報を取得する関数です。
この関数は RAG スペースに登録されたデータの情報も返すため、登録データの確認のために利用することもできます。
- [プロンプトテンプレートを構成] スクリプトステップ
- AI 関連のスクリプトステップでプロンプトテンプレートを設定します。
- プロンプトテンプレートについては、このスクリプトステップを使用しない場合でも裏側でデフォルトのテンプレートが自動挿入されますが、このスクリプトステップでテンプレートをカスタマイズして AI からの応答の一貫性をさらに高めることができます。
なお、これから確認していくカスタム App のスクリプトは、いずれも、冒頭に [RAG アカウント設定] スクリプトステップが含まれていますが、この設定はスクリプトステップを実行後ファイルが閉じられるまで有効となるため、運用環境では起動時などに一度実行すれば十分です。例えば、[RAG アカウント設定] スクリプトステップを OnFirstWindowOpen スクリプトトリガから実行したり、サブスクリプトとして呼び出すことでアカウント設定を一元管理できます。
この後は、サンプルのカスタム App を使って確認していきましょう。サンプルファイルはこちらからダウンロードいただけます。
3.2. RAG スペースへのデータの登録
今回使用するカスタム App では、「社内規程」という名前の RAG スペースに、就業規則、出張経費規程、福利厚生規程など、社内規程に関する複数の文書を登録し、社員が自然文で知りたいことを尋ねて回答を得られるようにしています。まず、RAG スペースにデータを登録するところから見ていきます。
FileMaker の RAG スペースでサポートされているファイル形式は PDF ファイルとテキストデータであるため、Word で作成された文書は PDF に変換したものを使用します。データを登録するには、登録・削除用のレイアウト([RAG スペースに登録・削除] 画面)で、PDF ファイルを [PDF] フィールドに直接ドラッグするか、または、テキストデータを [テキスト] フィールドに貼り付けて、[登録] ボタンをクリックします。下の図は、出張経費規程の PDF を登録した状態を示しています。
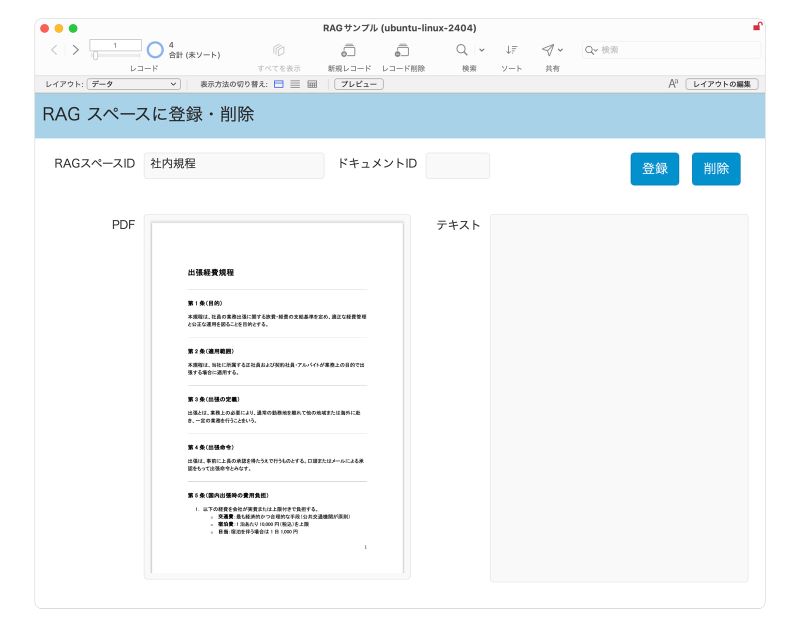
カスタム App の [RAG スペースに登録・削除] 画面
このレイアウトには、オブジェクトフィールドに保存した PDF を RAG に登録する、以下のようなスクリプトが設定されています。先ほど紹介した [RAG アカウント設定] スクリプトステップと [RAG 処理を実行] スクリプトステップが使用され、[RAG 処理を実行] スクリプトステップの [処理] オプションでは [データを追加]が選択されていることを確認してください。
※スクリプト上では、「RAG スペース ID」は、「スペース ID」と表記されます。

なお、RAG スペースへのデータの登録において、すでに RAG スペースに存在するファイルと同じファイル名の PDF を追加した場合は、新しいドキュメント ID が付与されて再登録され、既存のファイルは削除されます。
3.3. RAG スペースの情報の確認
続いて、RAG スペースの情報を確認する手順もチェックしておきましょう。使用するのは、GetRAGSpaceInfo関数です。この関数は、RAG アカウント名とスペース ID を引数にとりますが、スペース ID の指定はオプションです。スペース ID を省略した場合は RAG アカウント名にひもづくすべての RAG スペースの情報が返され、スペース ID を指定した場合はそのスペースの詳細情報が返されます。次に、それぞれの具体例を示します。
1)RAG アカウント名のみを指定
まず、スペース ID を省略し、RAG アカウント名だけを指定した場合の例です。

この場合、この RAG アカウント(「RAG」)で現在作成されているすべての RAG スペースを対象に、次の情報が返ってきます。
- スペース ID
- 使用している埋め込みモデル
例えば、以下の実行結果からは、「社内規程」という RAG スペースで「paraphrase-multilingual-MiniLM-L12-v2」というモデルが使用されていることがわかります。

ちなみに、RAG スペースにデータを登録する前は rag_space_list の配列には何も入っていません。

2)RAG アカウント名とスペース ID を指定
次は、RAG アカウント名とスペース ID を指定した場合の例です。

実行結果では、この RAG スペース(「社内規程」)に関する、次のような情報が返ってきます。
- スペース ID
- 使用している埋め込みモデル
- 登録されているドキュメント数
- ドキュメント ID
- ファイル名
なお、PDF ではなくテキストとして登録を行った場合は、テキストそのものが表示されます。

また、指定したスペース ID が存在しない場合は、次のようなエラーが返ります。

このように、 GetRAGSpaceInfo 関数を利用すれば、RAG スペースの状態を簡単に確認できます。
3.4. RAG スペースのデータの削除
RAG スペースに登録したデータが不要になった場合の削除手順についても確認しましょう。削除では、[RAG 処理を実行] スクリプトステップを使用します。[処理] オプションで [データを取り除く] を選択し、RAG スペースから削除する対象に応じて、以下1)、2)のいずれかの設定を行います。
1)RAG スペース内のすべてのデータを削除する
RAG スペース内にあるすべてのデータを削除するには、[引数:] オプションで削除対象のデータのドキュメント ID を指定せず、RAG アカウント名とスペース ID のみを指定します。これは、テスト環境をリセットしたい場合などに便利です。

2)RAG スペース内の特定のデータを削除する
[引数:] オプションでドキュメント ID を指定すると、そのドキュメントだけを削除できます。削除対象のドキュメント ID は、以下のように JSON オブジェクトとして指定します。

ドキュメント ID が「3」のデータを削除する場合は以下のように指定します。

このように、RAG スペースからデータを削除する場合はドキュメント ID が必要になります。ドキュメント ID は、GetRAGSpaceInfo 関数を使って都度確認することもできますが、ドキュメント登録時にカスタム App 内に保存しておくようにすると便利です。
4. 質問から適切な回答を得る
ここまで、RAG で使用するデータの扱いに関する手順や注意点について解説してきました。ここからは、いよいよ RAG の本来の目的である「質問と回答」、つまり、RAG に 質問(プロンプト)を送信して適切な回答を取得するまでの処理について確認します。
4.1. 「質問〜回答」の処理の流れ
まず、RAG の処理の流れを簡単に整理してみましょう。
- カスタム App にユーザが質問を入力し、送信する
- RAG スペース内で セマンティック検索(意味検索) が行われる
- 関連性の高い文書が抽出される
- 抽出された内容が AI モデルに対するプロンプトに追加される
- AI モデルが回答を生成する
- 生成結果がフィールドに保存される
※ 2 〜 5 の処理は裏側で行われる処理であり、ユーザには見えません。
ここで特に重要なのが 2 のセマンティック検索(意味検索)です。
これは単純なキーワード検索とは異なり、文章の意味的な近さをもとに関連する情報を探す検索方法で、ユーザの質問と完全に同じ単語が含まれていなくても、関連性の高い情報を見つけることができます。
さらに、検索で見つかった情報はそのまま表示されるのではなく、AI モデルへのプロンプトに追加され、AI モデルでは、「ユーザの質問 + 検索結果」をまとめて参照した上で回答を生成します。一般的な生成 AI ではモデルが持つ学習済みの知識だけに頼ることになりますが、この仕組みでは、自分たちの組織内にあるデータを根拠に回答を導くことが可能です。
4.2. 質問を送信して、回答を得るためのスクリプト
では、実際のスクリプトを見てみましょう。
RAG では、検索で取得した情報をいったん AI モデルに渡して回答を生成するため、スクリプトでは、まず、[AI アカウント設定] スクリプトステップで使用する AI モデルを指定します。そして、[RAG 処理を実行] スクリプトステップを使い、[処理] オプションで [プロンプトを送信] を選択します。AI モデルは、今回は OpenAI 社の gpt-4o を使用します。

上記の設定により、下の図のように、社内規程から検索した結果を自然文で得ることができます。
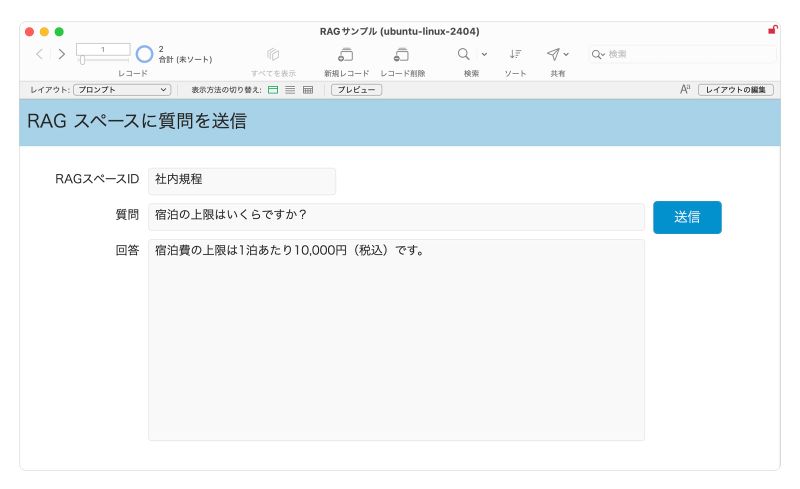
カスタム Appの [RAG スペースに質問を送信] 画面
4.3. プロンプトのカスタマイズ
FileMaker の RAG 機能においては、AI モデルはデフォルトでは RAG スペースからの情報のみに基づいて回答を生成します。これは、AI モデルへのプロンプトの中でそう指示されているためです。これを変更したい(AI モデルそのものが持つ事前学習済み知識も使いたい)場合は、[プロンプトテンプレートを構成] スクリプトステップを使用してプロンプトをカスタマイズすることができます。
[プロンプトテンプレートを構成] スクリプトステップ内の RAG プロンプトでは、デフォルトで以下のプロンプトが指定されています。

これを日本語に訳すと、以下のようになります。

冒頭の「質問に対して、与えられたコンテキストのみに基づき」という指示により、RAG スペースに登録された情報だけに基づいて回答が生成されます。もし、AI モデルが持つ学習済みの知識も利用して回答を生成したい場合は、「与えられたコンテキストのみに基づき(based on the Context only)」の部分を削除することで動作が変わります。ただし、事前学習済み知識が混ざることで、質問に対して期待したような回答が得られない、という状況になることも想定されます。どちらが用途に合った動作なのか、テストを行いながら判断するのがよいでしょう。
5. RAGを運用する上での重要なポイント
ここまで、RAG にデータを登録して利用する一連の流れを確認してきました。RAG は、設定自体はそれほど難しくありませんが、実際の運用にあたっては、以下のような観点での対応も必要になります。
5.1. データの取り扱いポリシーに則して AI モデルを選ぶ
RAG を導入する際に必須となるのが、組織におけるデータの取り扱いポリシーを確認し、ポリシーに準拠した AI モデルを選定することです。
今回はテキスト生成に OpenAI 社の API を使用しましたが、この場合、RAG スペース自体は社内の FileMaker Server 上にあっても、最終的なテキスト生成の際にクラウドサービスへデータが送信されます。「RAG の対象にしたい情報があるが、ポリシー上、外部への送信が厳格に禁じられている」という場合は、ローカル LLM(ローカルで動作する AI モデル)の利用も検討しましょう。
ローカル LLM については今後のブログでご紹介する予定です。
5.2. RAG スペースを整備し、ユーザにわかりやすいインターフェースを提供する
RAG を設定、導入しても、利用してもらえなければ意味がありません。ユーザに「この機能は使える」と感じてもらうためには、以下のような対応が求められます。
- どのような RAG スペースを作成し、各 RAG スペースにどの情報を登録するのか、事前に整理した上で設定を行うようにします。
- 質問用のレイアウトでは、「RAG」や「RAG スペース」と言われても一般のユーザには伝わりません。質問用のレイアウトでは何を行うことができて、また、どのような文書が登録されているのかが、ユーザに明確に伝わるようにします。
上記のような対応が不足した場合、ユーザが的確に画面を操作できず(社内規程類を含んだ RAG スペースに対して顧客に関する質問をしてしまうなど)、その結果、「わかりません」という回答が生成され、ユーザに「これは使えない!」と思われてしまう、という事態を招きかねません。導入を成功させるためには、常に「ユーザに使ってもらえるインターフェースになっているか」という視点を忘れないようにしてください。
6. おわりに
「設定編」と「利用編」の 2回にわたり、FileMaker 2025 の RAG 機能を紹介しました。カスタム App で RAG を利用すれば、検索対象となる情報をすばやく検索できるようになり、生産性を高められます。組織や業務の要件に合わせた RAG の活用シナリオをイメージしながら、まずはテストで動かしてみましょう。
なお、FileMaker Server 2025 をお持ちでない方は、45 日間使える無料体験版をダウンロードして試してみてください!