
目次
- はじめに
- 回帰モデルとは?
- トレーニングデータの準備
- 回帰モデルの作成
- 回帰モデルの検証
- 新規データで推論実行
- おわりに
1. はじめに
このブログでは、以前公開したブログ「Claris FileMaker 2025 - AI を活用するための新機能」にある FileMaker の AI 機能の中から、「過去のデータから未来の結果を予測する」ことができる回帰モデルの活用についてご紹介します。こちらの機能は「Claris FileMaker - 10分でスキルアップ」の動画でもご紹介しています。ぜひあわせてご覧ください。
動画「Claris FileMaker 2025 で AI 活用:[回帰モデルを構成] - 入門 -」
2. 回帰モデルとは?
回帰モデルについて理解するには、まず「回帰分析」という統計手法について(なんとなくでよいので)理解しておく必要があります。何か難しそうな印象を受けますが、中身は意外にもシンプルなのでご安心ください。
回帰分析とは、ある結果(数値)を、複数の要因から予測するための手法で、機械学習における代表的な手法の 1つです。例えば、「契約内容から契約が何か月くらい続くかを予測したい」場合、過去の「契約内容」と「実際の契約月数」の関係性やパターンをモデルに学習させます。これにより、新しい契約に対して継続月数を予測できるようになります。
この例以外にも、いろいろなシーンでのユースケースが考えられます。
- 【製造業】過去の生産データ(設備情報、材料情報、作業環境など)から不良率を予測
- 【不動産】過去の物件データや売買成約データから販売物件の適正な価格を予測
- 【小売・飲食】過去の販売データ、天候、実施キャンペーン等のデータから売上を予測
まさに、過去から未来を予測する手法、と言えますね。
ちなみに、皆さんお馴染みの生成 AI でよく利用される LLM(大規模言語モデル)と、今回の回帰モデルは全く別のものですので混同してしまわないように注意しましょう。LLM はその名の通り言語能力に特化したものである一方、回帰モデルは回帰分析に特化したもので 、できることや利用目的が異なります。
実は、回帰モデル自体は、Core ML(Apple が提供する機械学習フレームワーク)との連携機能が追加された FileMaker バージョン 19 からすでに利用可能でした。Create ML という無料のツールを使って非常に手軽に回帰モデルを作成し、カスタム App 上で推論を実行できます(こちらの機能は過去のブログをご参考にしてください)。ただし、モデルの作成(トレーニング)はカスタム App 上では行えないため、再学習させたい場合は Create ML でモデルを作成し直す必要があります。また、macOS のみの対応となります。
一方、今回の回帰モデルの機能は Windows でも利用できるほか、推論だけでなくモデルの作成もスクリプトから実行できます。つまり、日々 FileMaker に蓄積されるデータを活用してモデルをさらに賢くする再学習もカスタム App の中で行えます。
では、この回帰モデルを FileMaker 2025 ではどのように利用することができるのか、具体的に見ていきましょう。今回はこちらのサンプルファイルを使いながら機能や利用方法を深掘りします。このサンプルファイルは、過去の契約内容に基づいて、新しい契約がどの程度の契約月数を期待できるか、回帰モデルを使ってシミュレーションを行う、というものです。細かな実装方法については本ブログでは割愛させていただきますが、そのあたりはぜひ実際のファイルでご確認ください。
3. トレーニングデータの準備
モデルを作成するには、元になるデータ(トレーニングデータ)が必要になります。サンプルファイルでは、過去の契約情報(契約内容と通算契約月数)を 5,000件(*)用意しました。このうち 4,500件のデータを使って契約内容と契約月数のパターンをモデルに学習させてみましょう。残りの 500件は後ほどモデルの検証に利用します。
(*) 今回用意したデータは、契約内容と契約月数の間に一定の傾向が現れるように作成した疑似データです。一方で、現実のデータに近づけるために適度なランダム性も加えており、同じ契約条件でも契約月数が完全に一致しないような“ばらつき”も持たせています。
ここで、重要なポイントがあります。それは「回帰分析は数値データを利用する解析手法である」ということです。つまり、トレーニングデータは最終的には数値データである必要があり、テキストデータが含まれる場合はそのままでは利用できません。そこで用いる手法が「データを埋め込みベクトルに変換する」というものです。
トレーニングデータの埋め込みベクトルを作成
埋め込みベクトルとは、文章の意味をコンピュータが扱える数値の形に変換したものです。これにより、本来はそのままでは扱えないテキストデータも、回帰モデルなどで利用できるようになります。FileMaker で埋め込みベクトルを作成する方法についてはセマンティック検索に関する過去のブログなどでも解説しているので、そちらをご参照ください。
Claris エンジニアリングブログ:FileMaker 2024 で LLM を利用する
→「埋め込みベクトルの生成と保存」
今回のサンプルファイルのデータにはテキストが含まれますので、上記の埋め込みベクトルを利用する方法で進めていきます。
実際のデータを見てみましょう。「契約情報」画面には過去の契約内容とそれぞれの契約の通算契約月数が表示されています。このとき高齢者区分、配偶者の有無、契約タイプ、支払方法などが契約月数を決める「要因」となり、「特徴量」と呼びます。それに対して、結果である通算契約月数を「ターゲット値」と呼びます。ここで、FileMaker の仕様では、「要因」となる値には 1つのフィールドだけを指定できます。そのため、今回のように複数の特徴量がある場合は「それらを 1つのフィールドにまとめる」というのが設計上のポイントとなります。サンプルファイルでは画面右側の [契約情報](「c_契約情報」フィールド)がそれです。そして、このフィールドが埋め込みベクトルに変換する対象のフィールドとなります。
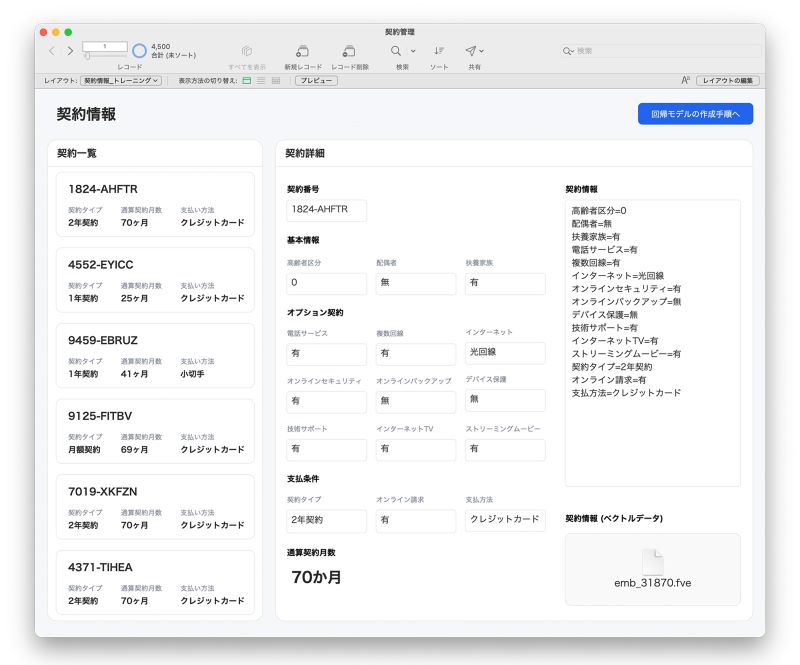
サンプルファイル - 「契約情報」画面
サンプルファイルでは、埋め込みベクトルの作成からその後の回帰モデルの作成、利用までを「回帰モデルの作成手順へ」レイアウトで操作できるようになっています。
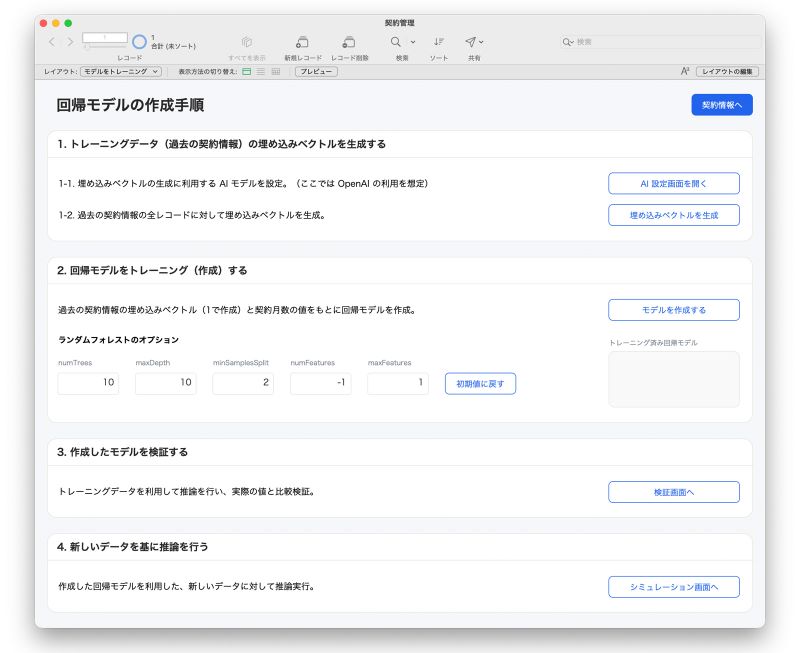
サンプルファイル - 「回帰モデルの作成手順」画面
埋め込みベクトルの作成には AI(LLM)の力を借りる必要がありますので、まずは事前設定として、利用する AI の設定を行います。[AI 設定画面を開く] ボタンから設定画面を開き、必要情報を入力してください。(アカウント名と埋め込みモデル名はデフォルトのままでも問題ありません。)その後、[埋め込みベクトルを生成] ボタンをクリックすると 4,500件の契約情報それぞれに対して契約内容の埋め込みベクトルが生成され、オブジェクトフィールドに保存されます。(2~3分程度かかります)
※ サンプルファイルでは OpenAI のテキスト埋め込みモデルを利用することを前提にしています。別の AI を利用する場合は適宜「埋め込みを挿入」スクリプトを編集してください。(「回帰モデルの検証_埋め込みを挿入」と「契約月数シミュレーション_埋め込みを挿入」スクリプトも同様です。)
※ サンプルファイルにはあらかじめ埋め込みベクトルを保存していますので API キーをお持ちでない場合でも体験いただけるようになっています。
4. 回帰モデルの作成
ここまでのステップで、モデルの作成に必要な以下のデータが揃いました。
- 過去の契約内容:利用する特徴量を1つのテキストにまとめて、その埋め込みベクトルを生成
- 各契約に対する契約月数:これは元々データとして持っていたもの
回帰モデルの作成
回帰モデルを作成するには [回帰モデルを構成] スクリプトステップを使用します。このスクリプトステップの詳細はヘルプをご覧いただくとして、今回は「モデルをトレーニング」スクリプト内で以下のようにオプションが設定されています。
- [処理:]:ここではモデルの作成(トレーニング)を行うので、[モデルをトレーニング] を指定。
- [モデル名:]:任意の名前で OK なので、「keiyaku」としておきます。
- [アルゴリズム:]:本ブログ執筆時点で選択できるのは [ランダムフォレスト] のみです。
- [ベクトルフィールドをトレーニング]:「契約情報ベクトル」フィールドを指定。
- [ターゲットフィールドをトレーニング]:「通算契約月数」フィールドを指定しています。
- [空または無効なレコードをスキップ]:有効。
- [引数:]:numTrees、maxDepth、minSamplesSplit、maxFeatures、numFeatures の各フィールドの値を基に JSON にしています。
- [モデルの保存先:]:「回帰モデル」テーブルの「モデル」フィールドを指定。
では、「回帰モデルの作成手順」画面の [モデルを作成する] ボタンをクリックしてモデルの作成を行ってみましょう。[ランダムフォレストのオプション] の各パラメータはまずは初期値で実行します。トレーニングに要する時間は、レコード件数や特徴量の多さ、ランダムフォレストの各パラメータの値など、いろいろなものに影響を受けますが、特に今回はトレーニングデータが 4,500件ありますので、場合によっては数分程度かかるかもしれません。トレーニングが完了すると、レイアウト上の「トレーニング済み回帰モデル」にモデル(reg_XXXXX.fmreg)が保存されているのがわかります。これが、トレーニングデータの傾向やパターンを学習した回帰モデルのファイルです。
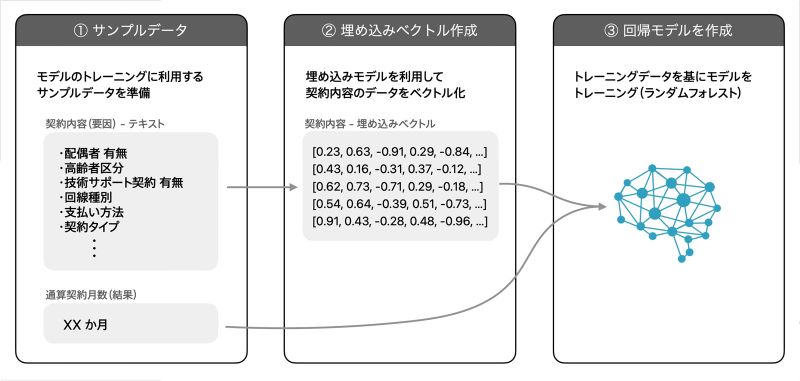
回帰モデルの作成の流れ(例:契約月数を予測するモデル)
5. 回帰モデルの検証
モデルは作成できましたが、実際に利用する前にそのモデルの精度をしっかりと「検証」することが重要です。一般的には、実際のデータのうち一部のデータを検証データとしておき、それ以外のデータをトレーニングデータとしてトレーニングに利用します。モデルの作成後、検証データに対して推論を行い、実際の値と比較することでその精度を評価します。モデルの精度が高ければ推論結果は実際の値に近くなるはず、ということですね。
検証データの埋め込みベクトルを作成
「回帰モデルの作成手順」画面の「検証画面へ」ボタンから検証画面に切り替えてみましょう。検証用の契約情報レコード(500件)が並んでいます。モデルをトレーニングするときと同様、推論の実行にも埋め込みベクトルを使用します。注意点として、契約内容をまとめたテキストのフォーマットや利用する埋め込みモデルはトレーニングの時と全く同じにする必要があります。
ここではまだ検証データに対して埋め込みベクトルが作成されていないので、まずは画面上部にある「埋め込みを挿入」ボタンをクリックして全レコードに対して埋め込みベクトルの作成をしましょう。10~20秒程度で完了するかと思います。これで検証の準備ができました。
モデルのロード
回帰モデルを利用する時は、あらかじめモデルをメモリ上にロードしておく必要があります。FileMaker では [回帰モデルを構成] スクリプトステップの [処理:] アクションで [モデルをロード] を指定することでモデルをロードできます。また、[モデルをアンロード] を指定するとモデルをアンロードできます。なお、このスクリプトステップでモデルをトレーニングした場合、トレーニング完了後に自動的にモデルがロードされるので、その場合は改めてロードする必要はありません。
検証データに対して推論を実行
推論を行うには PredictFromModel 関数を利用します。指定するオプションとしては、以下の 2つだけなので比較的シンプルな関数です。
- ロードしているモデルのモデル名
- 推論に利用するインプットデータ(ここでは検証データ)の埋め込みベクトル
サンプルファイルにある [推論実行] ボタンでは、検証データの全レコードに対して、今作成した回帰モデルを利用して契約月数を予測します。予測値は各行の [予測月数] に表示されるので、その値と [実績月数] に表示されている実際の月数を比較してみましょう。
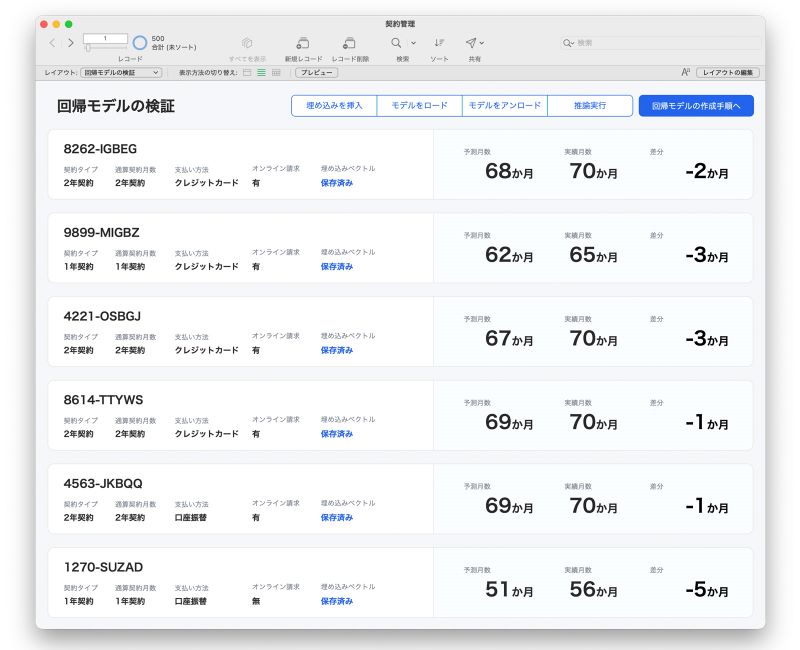
サンプルファイル - 検証データに対する推論結果
全体の結果を見ると、実際の月数と大きなズレがあるものもありますが、概ね実績月数に近い予測結果が得られており、契約内容と契約月数の関係性についてある程度の傾向が捉えられていることがわかります。ランダムフォレストのパラメータ調整により、さらに精度を高くすることもできるかもしれません。
なお、モデルの精度は、平均二乗誤差(MSE)や平均絶対誤差(MAE)、決定係数(R²)といった指標を用いて評価することができます。このあたりについても冒頭でご紹介した「Claris FileMaker - 10分でスキルアップ」の動画の中で触れられていますので参考にしてください。
トレーニングデータと精度の関係
トレーニング時のパラメータ設定でモデルの精度改善は可能とはいえ、トレーニングデータによっては十分な精度が出ない可能性もあります。というのも現実のケースでは多くの場合、結果に影響を与えているすべての特徴量を把握することが困難、という事情があるためです。例えば、今回の例だとトレーニングデータには含まれない以下のような要素も契約月数に影響を与えているかもしれません。
- インターネット回線の品質
- 技術サポートの対応品質
- 競合他社の乗り換えキャンペーン
- 営業担当者の更新フォロー活動
特徴量の数が多ければ多いほど精度は上がるかもしれませんが、一方でそれらのデータを集めるのが大変になってしまいます。実際に回帰モデルの活用を計画する際には、求める推測値と、どのような要素がそこに影響を与えているのか、そしてそれらのデータは既にあるのか、あるいは収集可能なのか、などを踏まえて検討するのがいいでしょう。
6. 新規データで推論実行
モデルの検証が終わったところで、実際に新しい契約内容に対して、契約月数を予測してみましょう。といっても、皆さんご想像の通りやることは先程の検証と同じです。つまり、以下のような処理内容になります。
- 契約内容(を1つのテキストにまとめたもの)を埋め込みベクトルに変換
- この埋め込みベクトルを基に、PredictFromModel 関数で推論実行
サンプルファイルの「契約月数シミュレーション」レイアウトでは、あらかじめ契約情報とその埋め込みベクトルを作成していますので、モデルがロードされている状態で [シミュレーションの実行] ボタンをクリックすると推論を行えます。
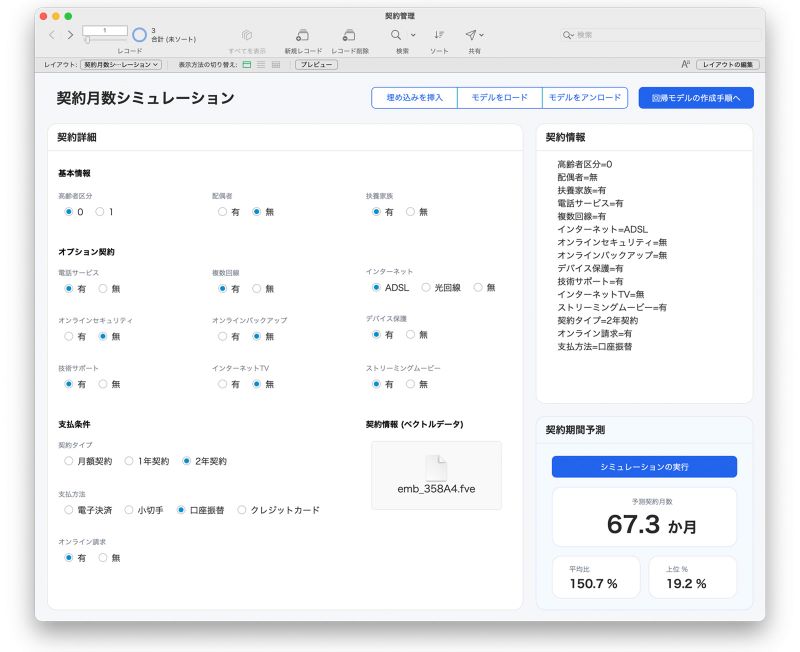
サンプルファイル - 「契約月数シミュレーション」画面
もしもご自身で埋め込みモデルをご利用可能であれば、契約内容を変えて「埋め込みを挿入」ボタンからベクトルを作成し直した上で再度推論を実行してみてください。変更した内容に応じて予測契約月数も変わることが確認できます。このような分析を行うことで、顧客への提案内容を検討したりキャンペーンを企画するなど実際の業務での活用もできるかもしれませんね。
7. おわりに
今回のブログでは、回帰分析という機械学習の手法を FileMaker 上で実現する方法をご紹介しました。改めて、機能としてのポイントは
- モデルのトレーニングから推論の実行、さらには新たなデータを使った再学習までを、FileMaker のカスタム App 内で完結でき、外部のツールが不要。
- トレーニングには FileMaker が持つ業務データを活用できる。
という点です。
FileMaker をご利用であれば、おそらく既にたくさんのデータが蓄積されているかと思います。それらのデータは日々の業務で利用される一方で、2次活用の大きな可能性も持っています。今回の回帰モデルの機能も、その可能性の 1つとして様々な業務シーンで活用いただけるのではないでしょうか。
FileMaker Server 2025 をお持ちでない方は、45日間使える無料体験版をダウンロードしてお試しください。