
目次
- はじめに
- [自然言語で SQL クエリーを実行] は何をしてくれるのか
- どんな仕組みなのか
- まずは最小構成で動かしてみる(クイックスタート)
- 効果的な設定のためのポイント
- 開発の進め方と、よくあるつまずき
- 実践イメージ(営業分析の例)
- ログを取ってプロンプトを育てる(運用と改善サイクル)
- まとめ〜成果を出すためのロードマップ
1. はじめに
このブログでは、「Claris FileMaker 2025 - AI を活用するための新機能」でご紹介した [自然言語で SQL クエリーを実行] スクリプトステップについて、実運用に向けたポイントを整理して解説します。
これまで、Claris FileMaker で複雑な集計を実行したり、複数テーブルにまたがる条件付きのデータの抽出といった高度なデータ探索を行うには、SQL(Structured Query Language)を使用したり、検索モードで条件を組み合わせたりする必要があり、現場のユーザにとってデータ活用のハードルになることもありました。
それを解消するのが、FileMaker 2025(バージョン 22)で追加された [自然言語で SQL クエリーを実行] スクリプトステップです。このスクリプトステップを利用すれば、話し言葉の質問から AI が SQL を生成してくれるため、求める結果をすばやく得られます。今回のブログでは、この新しいスクリプトステップの機能の概要から、実運用で期待した結果を安定的に得るためのポイントまでを掘り下げて説明しています。ぜひ、実際の活用シーンをイメージしながら読み進めてみてください。
2. [自然言語で SQL クエリーを実行] は何ができるのか
営業分析のカスタム App を例に考えてみましょう。
これまで
・ユーザが「先月の単価 50万円以上の確定受注について、1クリックで担当者別の件数と合計金額を出したい」と開発者に依頼する。
・開発者が検索条件・集計スクリプト・レイアウトを組み合わせて個別対応する。
・要望が増えるたびに、似たような集計スクリプトが量産される。
これから
カスタム App にグローバルフィールドを 1つ置き、[自然言語で SQL クエリーを実行] スクリプトステップを利用することで、次のように実現できます。
・ユーザが「先月の単価 50万円以上の確定受注を、担当者別に件数と合計で出して」と入力。
・スクリプトの機能により SQL が生成・実行され、結果を文章や表として返す。
・開発者はスキーマとプロンプトテンプレートを整えるだけで、集計の問いが変わっても同じ 1本のスクリプトで対応できる。
開発者視点でのイメージとしては、SQL を直接書くのではなく、「問い方」と「スキーマ設計」をチューニングするスタイルに変わる、と言えます。「似たような集計スクリプトを毎回作り足している」「ユーザからの問い合わせベースの集計に、開発が追いつかない」といった運用課題を抱える FileMaker 開発者ほど、この機能の恩恵は大きく感じられるはずです。具体的には、以下のようなメリットを得られるでしょう。
・SQL を書けない人でも「質問」から集計に近いことができる
例:「過去 12か月で売上が 100万円を超えた顧客を、地域別に集計したい」などを、自然言語で渡し、結果を文章やデータで受け取れる設計が可能です。
・開発者は「すべての集計パターン」を事前にスクリプト化しなくてよい
よくあるダッシュボード要望を、プロンプトとスキーマの設計でカバーしやすくなります。固定レポートに加え、一時的な分析の入口として強力です。
・処理の切り替えで用途を分けられる
スクリプトステップの [処理:] オプションにより取得する結果を指定できます。これにより、利用者向けは [処理: クエリー] で読みやすい文章を取得、バックオフィス向けは [処理: データのみを取得] で結果だけ、検証やデバッグ時は [処理: SQL を取得] で生成された SQL を確認、といった運用が実現できます。
・Web ビューアや JavaScript との連携(クライアント環境)
取得した結果を Web ビューアを利用して視覚的に表示する、といった拡張が可能です。
[自然言語で検索実行] スクリプトステップとの使い分け
ここで、同じく FileMaker 2025 で追加された AI 関連機能 [自然言語で検索実行] スクリプトステップとの違いを確認しておきましょう。両者の役割は以下のように異なります。

レイアウト上のレコードを「探す」体験は [自然言語で検索実行]、集計・横断的な問いは [自然言語で SQL クエリーを実行] という切り分けがわかりやすいです。別記事「自然言語でレコードを検索:Claris FileMaker 2025 - AI 活用」とあわせて読むと全体像がつかみやすくなります。
3. どんな仕組みなのか
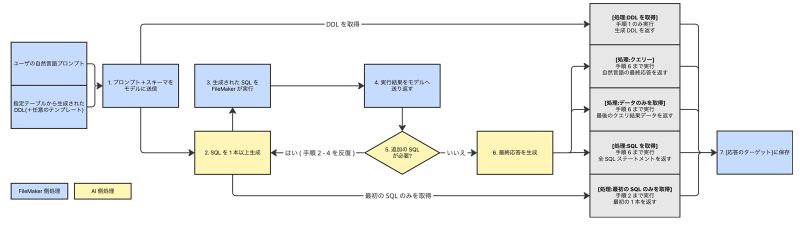
[自然言語で SQL クエリーを実行] スクリプトステップでは、自然言語のプロンプトと、指定したテーブルのデータベーススキーマ(DDL)をモデルに送り、モデルが生成した SQL を FileMaker が実行し、必要に応じて実行結果をモデルに返しながら、最終的な応答やデータを得ます。
この後は、Claris FileMaker Pro ヘルプ「自然言語で SQL クエリーを実行」の記載内容に基づき、設定項目とフローの概要を紹介します。
主な設定項目
このスクリプトステップには、以下のような設定項目が含まれています。

フロー
このスクリプトステップの典型的なフローは、以下のとおりです。
- プロンプトとスキーマ(および任意のプロンプトテンプレート)をモデルに送信する。
- モデルが 1本以上の SQL を生成して FileMaker に返す。
- FileMaker がその SQL を実行する。
- SQL の実行結果をモデルに送り返す。
- 必要なら 2〜4 を繰り返す。(複雑な質問への対応)
- モデルが最終応答を生成して FileMaker に返す。
- 返された応答が [応答のターゲット:] に保存される。
なお、[処理:] オプションには以下の 5つの値が用意されており、このフロー上のどの段階で結果を切り出すかを選ぶスイッチの役割を果たします。
- DDL を取得 … 手順 1 のみ実行(モデル呼び出しなし)。AI に渡す DDL を確認したいときに。
- 最初の SQL のみを取得 … 手順 1〜2 で停止。トークン消費を抑えてプロンプトを試したいときに。
- SQL を取得 … 手順 1〜6 を回しつつ、最終の自然言語応答までは進まず、生成された SQL ステートメント一覧を返す。
- データのみを取得 … 同じく手順 1〜6 を回し、最後の SQL の結果データのみ返す。
- クエリー … 手順 1〜6 の実行後、会話形式の応答を返す。
図にすると、FileMaker と AI モデルのあいだでは以下のようなやり取りが起きています。
4. まずは最小構成で動かしてみる(クイックスタート)
ドキュメントを読み込む前に、「まず動く最小形」を作ると理解が早まります。ここでは、Claris FileMaker Pro ヘルプ「自然言語で SQL クエリーを実行」の例 1 のスクリプトを、少しだけ省略した構成で試してみましょう。
4.1 . 手順
- OpenAI(または任意のプロバイダ)の API キーを用意する。
- 試したい 1 テーブル(例:顧客)の主キーや氏名、会社名などの最低限のフィールドコメントに [LLM] で始まる説明を付ける。
- 結果を格納する テキストフィールド(例:顧客::応答)か、変数を用意する。
- ボタンに次のようなスクリプトを割り当てる。

これだけで、自然言語の質問 → SQL 生成 → 実行 → 応答が 1本のスクリプトで動きます。
4.2. 次に触ってみたい 3つの切り替え
最小形が動いたら、以下を差し替えて挙動の違いを体感すると、本編の各章を読み進めやすくなります。
- [処理:] を「SQL を取得」に変えて、モデルが作った SQL 本体を見る
- [処理:] を「DDL を取得」に変えて、AI に渡しているスキーマを見る
- [データテーブル:] を「名前で」に変え、複数テーブルを改行区切りで指定して、結合クエリの応答を試す
動くところまで見届けると、「何が安全で、何がそうでないか」「どこをチューニングすべきか」の感覚がつかみやすくなります。
5. 効果的な設定のためのポイント
最小構成で概要をつかめたら、このスクリプトステップを最大限に活用するためのポイントを詳細に確認していきましょう。
5.1. FileMaker のデータと AI の間で送受信される情報の整理
「最初にモデルへ送るのはテーブル構造(スキーマ)であり、レコードの値は一切行かない」と考えがちですが、ワークフロー全体ではそう単純にはなりません。[処理: クエリー] のようにモデルと複数ラウンドやり取りする場合、クエリ結果に含まれるフィールドの値がモデル提供先に渡り得ます。一方で、初期送信は指定テーブルのスキーマに基づく DDL などに限定され、データベース全体が一括でモデルに送られるわけではありません。
スキーマとして何を渡すかと、クエリ結果として何がモデルに返るかは別の論点として整理すると良いです。設計時には次もあわせて検討してください。
- 利用するモデル・プロバイダの利用規約・データ取り扱い等
- どのテーブルをスキーマに含めるか、どのフィールドが結果に出るか(SELECT の範囲)
- クラウド利用が難しい場合のオンプレミス向け構成
なお、スキーマ、クエリ結果の要件はケースごとに異なるため、組織の法務・セキュリティポリシーに照らして判断することが安全です。
5.2. DDL の構成を知る
初期段階でモデルに渡る DDL は、指定テーブルとフィールド定義・コメントに基づきます。そのため、不要なテーブルを送らないようにしたり、[LLM] で DDL に含めるフィールドを絞ったりすることで、ノイズや意図しないフィールドの露出リスクを下げやすくなります。あわせて、データテーブルに含めるテーブル数やフィールドの広さは抑えたほうが、生成 SQL が FileMaker で通りやすくなります。
[処理: DDL を取得] で確認できる DDL の例(モデルに渡るスキーマのイメージ)
ここでいう DDL は、FileMaker が指定テーブルから自動生成する CREATE TABLE ... 形式のテキストです。FileMaker のリレーションシップグラフ、フィールド定義、フィールドコメントをもとに組み立てられ、AI が SQL を書くときの「参照資料」として使われます。
[処理: DDL を取得] を選ぶと、モデル呼び出しなしで このステップが生成する DDL テキストだけを [応答のターゲット:] に保存できます。デバッグで「AI に何が見えているか」をそのまま確認する用途として利用できます。
以下は、イメージをつかんでいただくためのサンプルです。なお、実際の文言はファイルのテーブル定義・リレーションシップ・フィールドコメントによって変わります。フィールドコメントに [LLM] を付けてフィールドを絞っている場合、生成 DDL のコメントには説明文だけが入り、[LLM]という文字列自体は DDL 上に出てきません(Claris FileMaker Pro ヘルプ「DDL および SQL クエリー生成におけるデータベーススキーマのベストプラクティス」参照)。手元のファイルでは必ず [処理: DDL を取得] の出力と照合してください。
1) 単一テーブルに絞った DDL の例
質問が「担当者別の件数」など 1 テーブルで足りる場合、data tables もそのテーブルだけにすると、モデルが JOIN や多段サブクエリに頼りにくくなります。

2) 複数テーブルと外部キーを含む DDL の例
「顧客ごとの受注金額」のように結合が必要な場合は、関連するテーブルが DDL に載り、外部キーが分かるとモデルが JOIN を組み立てやすくなります。

FOREIGN KEY や PRIMARY KEY が含まれるか、関連テーブルがどこまで DDL に載るかは、リレーションシップグラフ上の定義の影響を受けます。Claris FileMaker Pro ヘルプ「自然言語で SQL クエリーを実行」では、「両方のテーブルオカレンスが指定されている場合にのみ DDL に含まれる」など、リレーションシップまわりの条件も説明されていますのでご参照ください。同ヘルプの例 3 にある「製品」と「注文」の DDL は、典型的な 2 テーブル+外部キー の形の参考になります。

自然言語の質問から SQL を組み立てる AI は、まずこのような CREATE TABLE で表された「地図」を読み、SELECT・JOIN・WHERE・GROUP BY を推論します。コメントに「外部キー」「単位」などを書いておくほど、意図に沿ったクエリになりやすいです。
5.3. SQLの構成を知る
[処理: SQL を取得] で確認できる生成 SQL の例
[処理: SQL を取得] にすると、モデルが生成した SQL 文を変数やフィールドに保存できます(モデルとのやり取りは行いますが、最終の自然言語の応答までは進みません)。これは、デバッグで「どんな SQL が組み立てられたか」をレビューする用途で利用できます。
以下は、Claris FileMaker Pro ヘルプ「自然言語で SQL クエリーを実行」の例 3 で紹介されているもので、製品 ID 101 の注文合計を尋ねたときの生成例です。

なお、実際の出力では、モデルや質問によって複数の SQL が改行やセミコロンで連結されることもあります。エラーが出たときは、この結果と [処理: DDL を取得] の DDL をあわせて見ると原因を切り分けやすいです。
5.4. テーブルやフィールドは「広く渡しすぎない」ほうがよい
data tables に多くのテーブルを一度に指定すると、モデルはリレーションシップを活かそうとして複数の JOIN やサブクエリなど、見た目は合理的だが FileMaker の SQL 実行環境では解釈できない、もしくはサポート外の構文を含んだ SQL を出しがちです。
「とにかく全部のテーブルを渡せば賢く答えてくれる」わけではなく、渡したスキーマの広さに比例して SQL が複雑になりやすく、その結果、処理がうまくいかずエラーとなって再試行や別の生成にトークンを使う、というループに陥りかねません。
この場合、次のような工夫をすることで、エラー率とトークン消費の両方を下げることが可能になります。
- [LLM] で DDL に載せるフィールドを必要最小限にする。ノイズが減ると、モデルが「使えそうなフィールド」に集中しやすくなります。
- その質問に必要なテーブルだけを data tables(または [データテーブル: 名前で])に含める。分析用途ごとにスクリプトやボタンを分け、渡すテーブルセットを切り替える。
- [データテーブル: DDL で] に、手元で整えた短い DDLを渡し、モデルに見せる世界を意図的に狭める(高度だが、厳格に制御したい場合)。
- プロンプトテンプレートで、「サブクエリ禁止」「結合は 2 テーブルまで」など、FileMaker で通りやすい書き方を明示する(詳細は、Claris FileMaker Pro ヘルプ「プロンプトテンプレートを構成」を参照。このあとの章でも解説します)。
フィールドを絞る:[LLM] タグを使用
フィールドコメントの先頭に [LLM] を付けることにより、DDL にはそのフィールドだけが含まれ、コメントが [LLM]で始まらないフィールドは DDL から除外されます(詳細は、Claris FileMaker Pro ヘルプ「DDL および SQL クエリー生成におけるデータベーススキーマのベストプラクティス」を参照)。[LLM] タグの使用には、フィールドの絞り込みのほか、次のようなメリットがあります。
- トークンとコストの抑制 — DDL が短くなる
- ノイズ削減 / 露出範囲の抑制 — システム用フィールドや、機密情報を含むフィールドを送らない
- 意図の明示 — 外部キーや単位などをコメントで補足できる
なお、実装時には、リレーションシップまわりに関して以下のような点に注意が必要です。
- あるテーブルに [LLM] を 1つでも付けると、タグのないフィールドは DDL に出ません。そのため、主キー・外部キー・集計に使うフィールドには、抜けなく [LLM] と説明を付けるのが安全です。外部キーを DDL から落とすと、「顧客名でグループ化」のような SQL をモデルが組み立てにくくなります。
- 集計フィールドは SQL で誤結果になり得るため、ベストプラクティスでは [LLM] を付けず DDL から外し、通常フィールドの集計で代替することが推奨されています。
テーブルを絞る:JSON オプションでテーブルを動的に切り替え
Claris FileMaker Pro ヘルプ「自然言語で SQL クエリーを実行」の例 2 が「動的にテーブルを切り替える」パターンですので、こちらを使って解説しましょう。以下のスクリプトでは、[指定されたオプション: JSON データで]に渡す JSON で、data tables にテーブル名の配列を入れています。

- テーブル一覧はユーザの権限・画面コンテキストから Let や List で組み立て、JSONMakeArray に渡す文字列を切り替えます 。
- 処理の選択は query 、 query for data only の 2つです(ユーザに「説明文」と「生データ」のどちらが欲しいか選ばせる UI と相性がよいです)。
名前での「改行区切りのテキスト式」でも複数テーブルは指定できますが、実行時に中身を組み替えるなら JSON の方が拡張しやすいです。なお、テーブル名を動的に増やせるからといって、常に最大セットを渡す必要はありません。質問の種類に応じて配列を短く保つと、生成 SQL が安定しやすいです。
6. 開発の進め方と、よくあるつまずき
6.1. 開発の進め方
- [AI アカウント設定] スクリプトステップでプロバイダとキーを設定する(ローカル LLM ならエンドポイント)。
- [処理: DDL を取得] で実際にモデルに見えるスキーマを変数などに書き出し、[LLM] の付け忘れがないか確認する。
- [処理: 最初の SQL のみを取得] または [処理: SQL を取得] で、想定質問に対する SQL をレビューする。
- 問題があれば [プロンプトテンプレートを構成](テンプレートタイプは SQL クエリー)スクリプトステップで、FileMaker SQL の制約や禁止関数を追記する。
- [処理: データのみを取得] で戻り値の形式を確認し、最後に文章応答が必要なら [処理: クエリー] へ切り替える。
プロンプトテンプレートに関する考慮事項
- プロンプトテンプレートでは :schema:、:question:、:sql_query:、:sql_results: などの定数が使えます(テンプレートタイプと [処理:] により利用可能な定数は異なります)。詳細は、Claris FileMaker Pro ヘルプ「プロンプトテンプレートを構成 」を参照してください。相対日付(「今月」「先週」など)はモデルだけに任せると解釈がぶれやすいので、基準日をプロンプトやテンプレートに明示するか、Get ( 日付 ) を連結して渡すと安定しやすいです。
- FileMaker の ExecuteSQL 系の方言は PostgreSQL 等と完全一致しません。テンプレートで使ってほしくない関数(環境によっては使えない関数)や FETCH FIRST n ROWS ONLY の利用方針などを書いておくと、生成 SQL のブレを減らせます。テンプレート名を指定しない場合でも、二重引用符での識別子の囲み、FETCH FIRST の利用、LIKE と ILIKE の扱いなど、FileMaker 向けの前提がモデル側に渡る系統の既定があります。運用でルールを足す場合は、[プロンプトテンプレートを構成] の SQL クエリー タイプで追記します。カスタムテンプレート利用時に既定プロンプトとどう合成されるかは製品の挙動に依存するため、実ファイルで一度確認しておくと安心です。
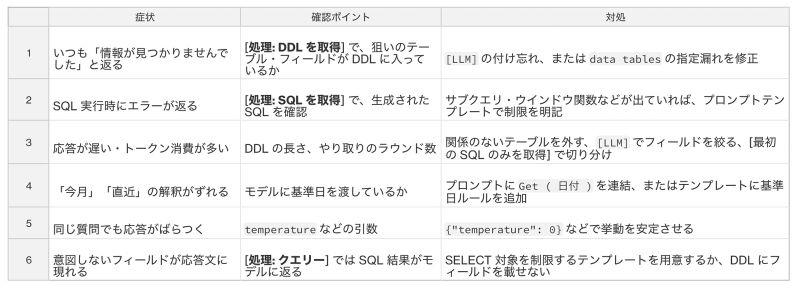
6.2. よくあるつまずきと対応
7. 実践イメージ(営業分析 App の例)
冒頭で触れた「先月の、単価 50万円以上の確定受注を、担当者別に集計」という要望に対し、AI が生成する SQL のイメージは次のようになります(モデルや質問の仕方で変わりますし、テーブル名・フィールド名は実際の定義に合わせます。FileMaker では識別子を二重引用符で囲むのが一般的です)。

別テーブルと結合する場合も、DDL にリレーションシップが含まれる条件を満たすと、モデルが JOIN を組みやすくなります。
同じ要望を [処理: クエリー] で実行すると、[応答のターゲット:] には次のような会話形式の文章が入ります(あくまでイメージです)。

「生データを表に出したい」といった場合は [処理: データのみを取得]、「SQL を自分でレビューしたい」場合は [処理: SQL を取得] に切り替える、という使い分けができます。
8. ログを取ってプロンプトを育てる(運用と改善サイクル)
[自然言語で SQL クエリーを実行] スクリプトステップの仕組みは、リリースして「終わり」ではなく、実際に使われるなかで育てていく機能です。ユーザがどのような言い回しで尋ねてくるか、どの質問で AI が詰まるか、どの SQL が FileMaker 側でエラーになるかは、ログを取ってはじめて見えてきます。ログが無いと「なんとなく使いにくい」「たまにエラーが出る」という感覚的な評価しか残らず、プロンプトテンプレートを改善する根拠が作れません。
8.1. なぜログが重要か
- 質問の傾向を把握する: ユーザが「先月」「今期」といった曖昧表現をどれくらい使うか、特定のドメイン用語(例: 「粗利」「ネット売上」)がどれくらい出るかを捉え、テンプレートの補強に活かせます。
- 失敗パターンを資産化する: 同じ種類のエラーが繰り返されているなら、プロンプトテンプレートに「禁止ルール」や「好ましい書き方」を追加することで、次回以降の失敗を未然に防げます。
- モデル変更時の比較: モデルやバージョン、テンプレートを差し替えたとき、ログがあれば「以前は通っていた質問が通らなくなった」といった差分を定量的に追えます。
- 説明責任とセキュリティ: [処理: クエリー] では SQL の実行結果がモデルに渡り得るため、どの質問でどんな SQL が実行されたかを残しておくことは、監査やインシデント対応の面でも有用です。
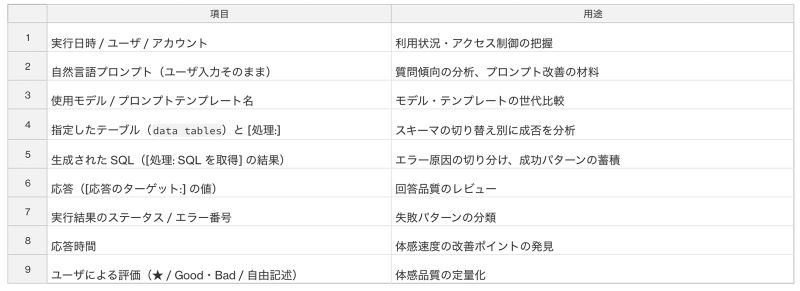
8.2. 何を記録するか(最低限おすすめしたい項目)
個人情報や機微情報が SQL 結果やプロンプトに含まれ得るため、ログテーブルにも権限設定を施し、保存期間・閲覧者を明示してください。
8.3. どう記録するか
方法 1:スクリプトで専用テーブルに記録する
専用の「AI 利用ログ」テーブルなどを用意し、次のような流れでレコードを作るのが基本形です。
- 実行前に、ユーザ入力・モデル名・テーブル指定などを変数に保持する。
- [自然言語で SQL クエリーを実行] スクリプトステップの直後に Get ( 最終エラー ) や応答時間などを取得する。
- 同じスクリプト内で [処理: SQL を取得] を別途呼ぶ、あるいは最初のスクリプトで「SQL を取得」→「データのみを取得」→「クエリー」と段階実行して各段の結果を変数に退避する。
- ログテーブルに新規レコードとして書き込む。
なお、[処理:] で 「SQL を取得」、「データのみを取得」、「クエリー」を別々に呼び出す場合、それぞれ独立した AI 呼び出しになるため、生成された SQL が完全に一致するとは限らないことに注意が必要です。検証用の代表質問では有効ですが、実際の 1回の問い合わせに対する監査ログとして扱う場合は、方法 2 の [AI 呼び出しログ設定] なども併用して確認します。
方法 2:[AI 呼び出しログ設定] スクリプトステップを使う
FileMaker 2025 には AI 呼び出しのログ出力そのものを制御する [AI 呼び出しログ設定] スクリプトステップが用意されています。詳細は Claris FileMaker Pro ヘルプ「AI 呼び出しログ設定」を参照してください。業務ログ(誰が・何を尋ねたか)は方法 1 のカスタムテーブルで、システム側の呼び出しログは方法 2 で、というように二層で残すと運用しやすくなります。
8.4. 改善サイクル(育てるためのプロセス)
1. 毎週 / 毎月、ログを振り返る
- 失敗した質問トップ N(エラー発生・「情報が見つかりませんでした」など)
- 時間がかかった質問、トークン消費が多かった質問
- ユーザ評価が低かった質問
2. 原因を分類する
- スキーマが不足(DDL に必要なフィールドが無い)→ フィールドコメントや [LLM] の整備
- 生成 SQL が FileMaker の SQL と合わない → プロンプトテンプレートに禁止事項・推奨事項を追記
- 質問自体が曖昧 → 入力する際の UI に質問サンプルを表示、用語集リンクなどで補助
3. 修正を適用し、効果を測る
- テンプレート更新前後で、同じ質問群のエラー率・平均応答時間・満足度を比較
- 悪化したパターンがあれば元に戻す、あるいはさらにルールを追加
4. ナレッジとして残す
- 「よく聞かれる質問」と「良い聞き方のコツ」をユーザ向けに公開
- 「避けるべき SQL」「推奨表現」を開発者向けに蓄積
プロンプトテンプレートは、運用の気づきを追記していく“生きたドキュメント”として扱うのが理想です。最初から完璧なテンプレートを作ろうとせず、実際の質問とエラーに触れながら、段階的にルールを加えていく姿勢で十分です。
8.5. ダッシュボードを作るなら
ログを溜めたら、次のような可視化を FileMaker のレイアウトや Web ビューアで作ると、改善の打ち手が見えやすくなります。
- 期間別の利用件数とエラー率の推移
- 頻出キーワードやプロンプト長の分布
- モデル・テンプレートの世代別成功率比較
- エラー種類別の件数(SQL エラー、情報が見つからない、タイムアウト等)
- ユーザ評価の平均値と、低評価コメントの一覧
同じ FileMaker 2025 の [自然言語で検索実行] や [モデルから応答を生成] スクリプトステップを組み合わせて、ログそのものを AI に問いかけられるダッシュボードにしておくと、改善の議論がさらにスムーズになります。
9. まとめ〜成果を出すためのロードマップ
最後に、このスクリプトステップを存分に活用して成果を上げるためのロードマップをご紹介しておきましょう。
フェーズ 1:準備(目安 1〜2 週間)
1. 分析に使うテーブルと主キー・外部キーの整理
2. [LLM] を付けるフィールド方針の決定
3. 用語の定義(「売上」「受注」など)
フェーズ 2:パイロット(目安 2〜4 週間)
1. 少数テーブルで [処理: DDL を取得] / [処理: SQL を取得] を回す
2. 代表質問リストで SQL と結果を検証
3. プロンプトテンプレートの追記
4. AI 利用ログテーブルを設計し、質問・生成 SQL・エラーの記録を開始する
フェーズ 3:展開(目安 1 か月〜)
1. data tables を動的に切り替え、部門別スキーマセットを試す
2. 利用上の注意(結果の人間による確認、トークンコスト)を UI に明示
3. ログの定期レビューを運用フローに組み込み、プロンプトテンプレートを継続的に改善する
ポイントは以下です。
- 最初の一歩は、第 4章のクイックスタートのように 1 テーブル・最小のスクリプトで動かすところから
- 次に [処理: DDL を取得] / [処理: SQL を取得] で「AI が見ている世界」を確認し、[LLM] タグで情報を絞る
- さらに、プロンプトテンプレートと動的な data tables で、用途別に精度とコストを最適化
- リリース後はログを取り続け、質問とエラーを見ながらプロンプトを育てる
なお、クエリ結果がモデルに返る点と、AI の回答は常に正しいとは限らない点は、利用規約・社内ポリシー・UI 上の注意書きとセットで設計してください。
以上、[自然言語で SQL クエリーを実行] スクリプトステップについて、活用のポイントをご紹介しました。このスクリプトステップは、蓄積データに対する「問い」を自然言語で載せ替えるための強力な部品です。開発者がスキーマとテンプレートを整えることで、ユーザは SQL を意識せずに分析に近い操作ができるため、データ活用のハードルは格段に下がります。ぜひ皆さんのカスタム App に取り入れ、新たな可能性を開きましょう。
FileMaker 2025 をまだお使いでない方は、まずは 45 日間使える無料体験版をダウンロードして、お試しください!